IJCRR - 6(22), November, 2014
Pages: 01-10
Date of Publication: 21-Nov-2014
Print Article
Download XML Download PDF
APPLICATION OF DATA MINING TECHNIQUES TO PROBLEMS IN FUND RAISING
Author: Adrian Udenze
Category: Technology
Abstract:Data mining in fund raising applications have been shown to significantly increase funds raised by charity organisations. This research investigates the accuracy of statistical classification techniques when applied to various prediction problems in fund raising. The results show that increased accuracy of predictions can be achieved by using actions taken by fund raisers as attributes as well as donor profiles. Where classification techniques fail, data mining results are shown to be useful for formulating and solving optimisation problems which are solved to provide the best course of actions for maximum return on investment.
Keywords: Data mining, Fund raising
Full Text:
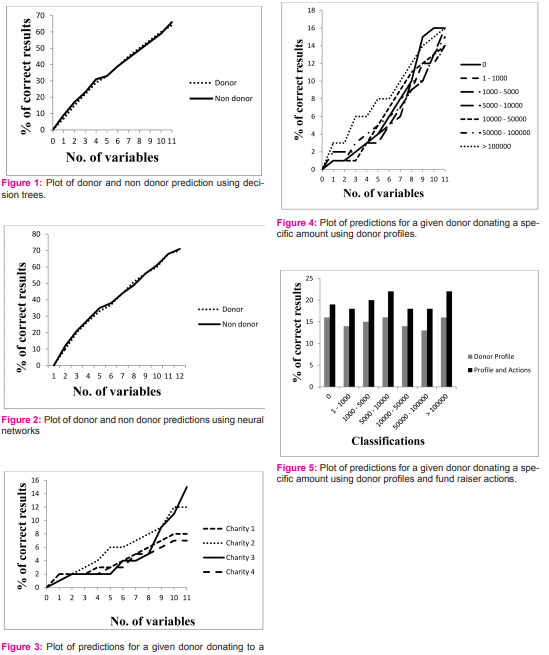
INTRODUCTION The total amount of money given in charity for the year 2012 in the United Kingdom was £9.2 billion according to the BBC [1]. With such a vast potential for attracting funds, charity organisations are increasingly making use of state of the art techniques in data mining to identify potential donors, increase donation amounts and maximise return on investments. In particular, fund raisers would like to be able to identify donors from a list and also, correctly predict how much a donor is likely to give. If fund raisers can correctly predict how much an individual will donate then they can ask for the optimal amount of money from each donor and also ensure that the right amount of resources are expended in acquiring those funds. In [2], the author uses donor profiles consisting of a number of donor related attributes to construct Decision Trees [3] and Neural Networks [4] for predicting donors and non donors. The author observes mixed results with better results for predicting non donors than for donors. The work presented here builds on that research by providing a more in-depth investigation into the suitability of statistical classification techniques common in data mining for fund raising applications. In particular, the contributions of this work are as follows 1.) statistical classification techniques are shown to be suitable for predicting with reasonable certainty whether or not an individual will make a charitable donation depending on the profile attributes used. 2.) statistical classification techniques are shown however to have limitations on what can be predicted including which charity an individual will donate to and how much an individual will give. 3.) It is shown that whereas in [2] the author uses only donor attributes, actions taken by fund raisers have a correlation to amounts donated and can be used to improve accuracy of predictions. As far as the author is aware this is the first time the actions of the fund raiser are being considered as an attribute for classifying donors. 4.) Given that the aim of the data mining exercise within a charity organisation is to maximise funds by asking for the optimal amounts from donors and using minimal resources in so doing, in the absence of reliable prediction from conventional data mining classification techniques, the author shows that return on investment can still be improved on by formulating and solving an optimisation problem the result of which is a policy for carrying out actions that maximise return on investment. LITERATURE REVIEW Data mining has been shown to help organisations increase return on investment for given fundraising campaigns. In [5] the author shows results of a number of fundraising campaigns with data mining and without. The results show an average of 50% increase in amount raised per dollar spent for campaigns with statistical analysis. In [6], the authors state that data mining can improve existing models by finding additional important variables, identifying interaction terms and detect ing nonlinear relationships. Data mining is also useful in making sure that a fund raising officer asks for the right amount of money from a given prospect [7]. In [2] the author attempts to predict prospect donor amounts based on data collected on previous campaigns using decision trees and neural networks. The author concludes that neural networks give a slightly more accurate prediction however he observes that increased accuracy of donors may be obtained by collecting more data. Decision trees [3] are a common approach to discovering logical patterns within data sets. A tree is built using Binary Recursive Partitioning based on an iterative process of splitting a set of pre-classified test data into homogeneous segments and then splitting each segment or branch of the tree into more segments. The end result is a model of the test data that classifies each observation which can then be used for the classification of other records. Neural networks have been used extensively for data mining in various fields of science ranging from medical diagnostics, to online real time financial systems [4]. Their ability to model relationships in data make them useful for classifying tasks as well as predicting future events. Supervised learning usually takes the form of adjusting weights in a neuron such that the difference between network outputs when compared to desired outputs are minimised at which stage the network is fully trained and can be used for predicting or classifying tasks. In unsupervised learning, weights are adjusted to match world events in real time. Operations research provides a decision making mechanism for problems of limited resources and have been used extensively in industry for optimising return on investment [8]. Numerous optimisation problems including scheduling tasks, optimal route finding and budgeting have been solved using operations research techniques. The work in this paper builds on the work in [2] and [6]. Results of classification of prospects using decision trees and neural networks are presented using donor profiles as done in [2]. Furthermore, this work shows that increased accuracy of prediction can be achieved using a new set of attributes namely, actions taken by fund raisers. The authors also show that by using the results of the classification exercise to formulate and solve an optimisation problem, return on investment can be maximised. METHODOLOGY The data set used for experiments was acquired from an international human rights organisation and consisted of details of past marketing campaigns. Records included profiles of donors as well as non donors. The data set consisted of 10,000 entries initially. The data was cleaned and records with incomplete or inaccurate data were deleted. A sample of the records used is shown in Table 1 below. The aim of this research was to model the data set such that the model could be used to predict as accurately as possible the following: 1. Charity donor and non donor. To predict from the data set which individual was likely to make a charitable contribution two classification models were used. First decision trees were constructed using the Tree package in R available from the cran.r project website at the time of writing [9] and then neural networks using the nnet package also available from the cran.r project website, for different numbers of variables. 70% of 1000 records of donors and 1000 records of non donors were used for training, the remaining 30% was set aside for testing. The resulting models from training were then used on the test data set for predictions; results are presented in the results section. 2. Donate to a given charity. Neural networks were constructed with 70% of 500 records each for four charities and 30% set aside for testing. The number of records used for training was limited by the number of records available. Test results are presented in the results section. 3. How much will a donor contribute to a given charity. The donor amount field was discretized and placed in 7 bins which were used as classes namely {0, 1-1000, 1000-5000, 5000-10000, 10000-50000, 50000-100000, >100000}. Thus, the aim was to predict in which one of the 7 bins or classes a prospect belonged. To ensure there was no bias in the results, equal numbers of records for each class was used in the data set. After selecting, transforming and cleaning the data the number of entries was reduced to 7000 i.e. 1000 for each class. Finally the data set was split into two, 70% for training and 30% for testing, results are presented in the results section. Next, actions taken by fundraisers were used as variables in addition to the donor variables. For a given campaign, several actions are available to the fund raisers e.g. telephone calling, emailing, organising events, carrying out an advertising campaign on radio or television. In addition, several of these actions may be undertaken e.g. send an email and then telephone. Results of the enhanced models are presented in the results section. 4. Finally, the results of the data mining exercise were used to formulate an optimisation problem which was then solved as a Linear Programming problem using the R package linear programming solver, available from the cran.r project website at the time of printing [9]. E.g. for a given marketing campaign, the fundraisers have a set of four actions {Telephone, Email, Organise an event, Email and Telephone, Telephone and Organise and Event}. Each action has an associated return on investment R and actions A have constraints C placed on them. The optimisation problem can then be formulated as Maximise R1 A1 + R2 A2 + R3 A3 + ... RnAn (1) Such that A1 + A2 + A3 ... 0, X2 > 0, x3 > 0, x4 > 0 Solving using linear programming, the result is obtained as 0x1 102.27x2 0x3 1.79x4. Objective = £2106.82 Translated as: Make 102.27 phone calls and organise 1.79 events and the campaign should realise £2106.82! This solution provides the best course of action to raise the most money. Note however that the campaign team cannot organise 1.79 events nor can they make 102.27 phone calls i.e. either 102 phone calls or 103 phone calls. To overcome this the solver is forced to return only integer values which provides a new result of 0x1 0x2 0x3 2x4 Objective = £1800. Translated as: Organise 2 events which will raise £1800! Results observed from test data using data mining as well as solving a formulated optimisation problem results in an increase of between 15% and 18% on return on investment compared to data mining alone. CONCLUSIONS Data mining for fund raising experiments using two classification techniques, decision trees and neural networks have shown to be effective in identifying potential donors but less so in identifying which charity an donor is likely to donate to and how much. The addition of actions taken by fund raisers to data mining variables increased accuracy of predictions compared to variables consisting of only donor profiles. The link between actions taken by fund raisers and donor amounts was explored further by formulating and solving a constrained decision prob- lem the result of which is a course of action that yields maximum return on investment. Future work will be on investigating modelling techniques for sparsely correlated data and using the models to formulate and solve constrained decision making problems in fund raising. ACKNOWLEDGEMENTS The author acknowledges the immense help received from the scholars whose articles are cited and included in references of this manuscript. The author is also grateful to the authors / editors / publishers of all those articles, journals and books where the literature for this article has been reviewed and discussed. The author also acknowledges the contributions of Amnesty International UK.
References:
1. BBC News. (2012) ‘Charity donations down 20%, UK Giving Report 2012, ‘www.bbc.co.uk/news/uk-20304267’ Accessed Nov 2014.
2. Heiat, N. (2011) ‘Data Mining Applications in Fund Raising’, in World Journal of Social Sciences, Vol. 1. No. 4. 14- 22.
3. Greenberg D, Pardo B., Hariharan K. And Gerber E. (2013) ‘Crowd funding support tools: predicting success and failure’, in Proceedings of Chi EA 13 Extended Abstracts on Human Donors Factors in Computing Systems, pages 1815- 1820, ACM New York.
4. Jain N. and Srivastava V. (2013) ‘Data Mining techniques: A survey paper’, in International Journal of Engineering and Technology’ Vol2. Issue 11.
5. Wylie, P. (2008) ‘Baseball, Fundraising, and the 80/20 Rule: Studies in Data Mining’ Washington, DC : CASE (Council for Advancement and Support of Education).
6. Devale, A. B. and Kulkarni, R. V. (2012) ‘Applications of data mining techniques in life insurance’, in International Journal of Data Mining and Knowledge Management Process (IJDKP) Vol.2, No.4: 31-40.
7. Birkholz, J. (2008) ‘Fundraising Analytics: Using Data to Guide Strategy’ 1st edition, John Wiley and Sons, Inc.
8. Xing Y. Li L. and Bi. Z. (2013) ‘Operations research in service industries: A comprehensive review’, in Systems Research and Behavioural Science, Special Issue: Systems Science in Industrial Sectors, Vol 30, Issue 3, pages 300 – 353.
9. Cran.r project (2014), ‘Linear Programming package’ in www.cran.r-project.org/web/packages, Accessed Nov 2014.

specific charity
|
 IJCRR
IJCRR 





 This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License





