IJCRR - 13(20), October, 2021
Pages: 136-142
Date of Publication: 24-Oct-2021
Print Article
Download XML Download PDF
Computational Medicine: A Review on Applicability of Machine Learning Techniques in Diagnosing Diseases
Author: Shah Alpa Kavin, Gulati Ravi
Category: Healthcare
Abstract:The digitalization of health informatics is revolutionizing the discipline of medicine. The advancements to extract knowledge from complex clinical digitized data have led to significant developments in health care. Machine Learning techniques can infer medically actionable knowledge that will support doctors and health care stakeholders to deduce the best possible medical decisions. Objective: To evaluate the applicability of the Machine Learning model in diagnosing the disease. Methods: A systematic review and literature survey to understand and elaborate the significant impacts on the prognosis, detection, and diagnosis of diseases by using various Machine Learning techniques is carried out. Result: Various Machine Learning models have been effectively been used in recent years for classifying patients and normal. A combination of bagging and boosting techniques can foster results and open newer avenues of accurate predictions. Conclusion: A thorough study of the various research undertaken in the domain of computational medicine, it was speculated that Machine Learning models are useful in applications for disease diagnosis involving complex clinical data.
Keywords: Machine learning, Supervised Learning, Support Vector Machines, Classification, Decision Trees, Computational medicine
Full Text:
INTRODUCTION
Computational medicine refers to the applications of computer-generated methods for the detection, diagnosis and prediction of diseases. In recent years, an unprecedented growth in the development of computational models, used as classification, prediction and diagnosis tools, have been witnessed. Machine Learning models have revolutionized the medical methods that serve as an invasive method in the prediction and detection of diseases. These methods can aid and can be the initial step in making the task inexpensive, giving numerical and accurate results in real-time.
Machine Learning task involves classifying a record that may be in the form of information in a flat file, or digitized images like Computed Tomography (CT) Scans, Mammography images, MRI images, Electronic Cardio Grams (ECGs), demographic information collected from hospitals, to name a few. Records of patients suffering from the disease are used to train the model. Once the model has been created, it can then be used to predict future unseen diseases. This automatic classification yields faster diagnosis, improving health standards. In remote areas of the country where the facility of specialists and hospitals might not be available in the nearby vicinity, these models can serve as clinical decision support systems for initial screening. Researchers work on developing efficient techniques for the detection of a disease; this might aid in early diagnosis of the disease, which otherwise could not be achieved because of the need for high accuracy and less execution time. Machine Learning has become a new kind of medical tool with the advancement of Information Technology 24 and has gained broader application prospects due to the rapid development of Electronic Health Records (HER). 25
This review paper is organized into the following sections. A brief overview of Machine Learning models is discussed in Section 2. Section 3 discusses various parameters used for evaluating the performance of the Machine Learning Model. Section 4 is the core of the paper that discusses the application of Machine Learning models for the prediction of diseases. Section 5 throws light on the challenges faced in implementing Machine Learning techniques. Finally, in Section 6, conclusions and future work perspectives are drawn.
A BRIEF OVERVIEW OF MACHINE LEARNING MODELS
Machine Learning is a computer program that learns and improves from the experiences that are in the form of past or historical data, performs a specific task and has a performance measure with which it performs. Machine Learning has varied applications in Healthcare, Insurance, Analytics, Recognition problems related to Images, Speech, and Video, to name a few. Machine Learning models can effectively help doctors and stakeholders to achieve their goals because of their fast and accurate recognition performance. These models help to classify whether the given record is suffering from a particular disease or not. For the sake of completeness, various algorithms that are used by researchers are discussed in brief.
Decision Trees (DT) is a versatile and powerful Machine Learning algorithm that performs both classification and regression tasks, capable of fitting complex datasets. In a decision tree, each internal node splits the instance space into two or more sub-spaces according to a discrete function of the input attributes values. Decision Trees are essential, and they form the basis for extended algorithms like Alternating Decision Trees and Random Forests.
The Alternating Decision Tree (ADT) is used for classifying and predicting labels in supervised learning. Traditional boosting decision tree algorithms such as CART and C4.5.22 have been successful in generating classifiers but the resulting decision trees created are complicated to interpret also. ADT combines the simplicity of a single decision tree with the effectiveness of boosting. Several weak hypotheses are merged to induce a boosted one. The classifier so created is easy to interpret for the classification rules.
Artificial Neural Networks (ANN) are robust classifiers that replicate the structure and functions of biological neural networks18 present in animal brains. An ANN is composed of connected units, also called nodes, which are inspired by neurons of biological brains. An ANN consists of an input layer, an output layer and one or more hidden layers. The Backpropagation Algorithm updates the weights of neurons to maximize classification accuracy. A Feed Forward Neural Network (FFNN) is a special type of ANN where the nodes of the structure do not form any cycle. The information moves only in one direction – forward – from the input nodes, through the hidden nodes and then finally to the output nodes.
Support Vector Machines (SVMs) is a non-probabilistic binary linear classifier. SVM constructs a hyperplane or set of hyperplanes in a high- or infinite-dimensional space to separate data19. It uses a kernel function for non-linear classification. The kernel maps data into the higher dimensionality that enables to obtain a better distribution, creating a better classification result. Various kernel functions like
Polynomial, Radial Basis Function (RBF) and Hyperbolic Tangent are used to reduce the generalization error of support-vector machines.
A Random Forest (RF) is an ensemble learning method that constructs a multitude of decision trees at training time and outputs the class that is the overall prediction of the individual trees 20. They are commonly used in classification and regression problems. RFs, help to rectify the overfitting problem of decision trees. They are efficient at working on large scale databases.
Naive Bayes (NB) algorithms are based on simple probabilistic classifiers that are based on Bayes' theorem with strong (naive) independence assumptions between the features under considerations21. Bayes classifiers are very efficient for solving the text categorization problems. They also have successful implications in automatic medical diagnosis.
K-Nearest Neighbor (K-NN) predicts the class label of new input. The algorithm uses the similarity of new input to its input samples in the training set.
Logistic Regression (LR) is applied for a binary classification problem to predict the value of determining variable y when y is [0, 1]. The negative class is represented by 0 and the positive class by 1.
PERFORMANCE INDICATORS FOR CLASSIFICATION PROBLEMS
Consider a model that is used to assess whether a person is suffering from chronic kidney disease17. Samples in the form of information based on attributes under consideration are available. The indicator True Positive (TP) indicates that samples are correctly diagnosed as suffering from chronic kidney disease. False Negative (FN) indicates that the samples were incorrectly diagnosed as suffering from chronic kidney disease. False Positive (FP) indicates the normal samples (not suffering from chronic kidney disease) and are incorrectly diagnosed. True Negative (TN) indicates the samples which were not having chronic kidney disease are correctly diagnosed as not having chronic kidney disease.
The Accuracy of this model will be the number of correctly predicted samples out of all the samples. Sensitivity or Recall is the metric that will evaluate a model’s ability to predict the True Positives of each class. Specificity is the metric that evaluates a model’s ability to predict the True Negatives of each class. Precision is the ratio between the True Positives and all the Positives. For our example, it would be the number of samples that are correctly identified as having a chronic disease out of all the samples having the disease. F1 Score is the harmonic mean of Precision and Recall. The following equations are used by various researchers to ascertain the performance of the model that has been created.

Fig. 1 shows a snapshot of WEKA Tool 28 used to display Accuracy, TP Rate, FP Rate, Precision, Recall, F-Measure (F1-Score) performed on Breast Cancer Wisconsin dataset using Decision Tree Algorithm.

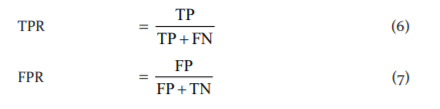
Other metrics used by researchers is Area Under the Curve (AUC) and Receiver Operating Characteristics (ROC) Curve. They are essential evaluation metrics that are used for checking any classification model’s performance. ROC is a probability curve, and AUC represents the degree or measure of separability. Higher the AUC, better is the model at predicting correct as correct and incorrect as incorrect. i.e. higher the AUC, the better will be the model in differentiating between the samples with chronic kidney disease and no disease. The ROC curve plots True Positive Rate (TPR) vs False Positive Rate (FPR) at different classification thresholds. And AUC measures the entire two-dimensional area underneath the entire ROC curve.
APPLICATIONS OF MACHINE LEARNING MODELS IN MEDICINE
This section discusses applications of Machine Learning models that were developed by the researchers in the detection of various diseases. The section highlights benchmark papers focusing on different aspects like the source of data, the research aim, Machine Learning techniques used, various features used to develop the model, and the outcome of the work done. The research in these fields is increasing steeply, and hence the authors recommend interested audiences to dig into them further, by picking up the disease of interest for further intended study.
Liyang Wei et al.1proposed the Machine Learning model to predict the automated classification of clustered microcalcifications (MCs). The researchers aimed to assist radiologists in the better diagnosis of breast cancer from mammograms. 697 clinical mammograms from the Department of Radiology at the University of Chicago were used to train the model. Eight features like number of MCs in the cluster, mean effective volume of individual MCs, area and circularity of the cluster, standard deviation from the effective thickness, area and volume and irregularity were used. Machine Learning algorithms like SVMs, Kernel Fischer Discriminant (KFD), Relevance Vector Machine, FFNN and Adaboost were employed on the training dataset. The accuracy of SVM (0.8545) was highest amongst all the implemented algorithms.
Q. Li et al.2 developed an algorithm for the classification of Ventricular Fibrillation (VF) and rapid Ventricular Tachycardia (VT) that can aid in an automatic external defibrillator and patient monitoring. 67 records with 99 channels from ECG databases (the American Heart Association Database, the Creighton University Ventricular Tachyarrhythmia Database, and the MIT-BIH Malignant Ventricular Arrhythmia Database) were used by the researchers to train, test and validate the model. 14 ventricular fibrillation metrics were used as feature-set. The Machine Learning model was based on SVM. The developed model achieved Accuracy of 96.3%±3.4%, Sensitivity of 96.2%±2.7%, and Specificity of 96.2% ± 4.6%, which surpassed the results that were reported by current methods.
Bum Ju Lee et al.3 worked in the identification of risk factors that are associated with cholesterol levels. The researchers used Serum High-Density Lipoprotein (HDL) and Low-Density Lipoprotein (LDL) cholesterol levels to identify the best predictors for HDL and LDL cholesterol levels. Women-HDL: 15 features, Women-LDL: 12 features, Men-HDL: 18 features and Men-LDL: 8 features were identified as anthropometric characteristics. The dataset comprised 13,014 Korean Adults. NB and LR were used to create Machine Learning models and were conceived as better initial screening tools for HDL and LDL cholesterol. The results were analysed based on the AUC curve which resulted, HDL-NB-WOMEN: 0.708, HDL-NB-MEN: 0.651, HDL-LR-WOMEN: 0.713, HDL-LR-MEN: 0.651, LDL-NB-WOMEN: 0.657, LDL-NB-MEN: 0.615, LDL-LR-WOMEN: 0.654 and LDL-LR-MEN: 0.605.
Jaime Melendez et al.4 developed a model to detect textural abnormalities related to Tuberculosis (TB). The dataset comprised of 917 chest radiographs collected from a busy urban health centre in Lusaka, Zambia. During training, labelled feature vectors were used to learn an appropriate classification rule by detecting textural abnormalities related to TB. The researchers developed a framework with Multiple-Instance Learner (MIL) classifier within an Active Learning (AL). The proposed method significantly improved the MIL based classification with AUC 0.877 at the pixel level. The work done by the researcher was superior in comparison to SVM with AUC 0.802 at the pixel level.4
The pioneering work to analyse the predictive powers of phenotypes consisting of triglyceride (TG) levels and various anthropometric indices in predicting Type 2 diabetes was done by Bum Ju Lee et al.5 The researchers developed a clinical decision support system for the initial screening of Type 2 diabetes. The study was done on 11,937 Korean Adults (4,906 males and 7,031 females) collected from Korean Health and Genome Epidemiology Study database. 21 features were studied and were analysed through statistical inferences. NB and LR algorithms were used to evaluate the predictive accuracy of different phenotypes. The results were analysed by AUC, which resulted in 1) For men: AUC by NB = 0.653, AUC by LR = 0.661 and 2) For women: AUC by NB = 0.73, AUC by LR = 0.735.
EminaAlickovic and Abdulhamit Subasi6 used ECG heartbeat signal classification for the diagnosis of heart arrhythmia. They used RFs for creating the predictive model. The Accuracy for the MIT-BIH database achieved was 99.33% and for St. -Petersburg Institute of Cardiological Technics database was 99.95 %.
ZerinaMasetic and Abdulhamit Subasi7 worked to classify normal and congestive heart failure. The features were selected using the Autoregressive Burg Method. RF yielded 100% accuracy in predicting congestive heart failure.
Acute Kidney Injury (AKI) is a common occurrence in hospitalized older adults, which may result in progressive deterioration of renal function. Work done by Rohit J. Kate et al. 8 created a Machine Learning model based on LR for the detection of AKI. The data was collected from 25,521 adults having age > 60 years from Aurora Health Care, Inc. in one calendar year. 12 Demographics, 9 Laboratories, 12 Medications and 14 Comorbidities features were used in the model. The study done by the researchers was the first study that examined the difference between prediction and detection of AKI. With results of AUC = 0.743 for detection at a 95% confidence level, LR surpassed the results obtained by NB, DT, SVM and ensemble models.
33 brain volumetric measures, 14 hippocampal subregional volumetric measures, 66 regional cortical thickness measures were considered for 240 MRI images for brain imaging and general cognition for dementia. LaugeSørensenet al.9 used ensemble methods with bagging and feature selection to improve the performance of dementia classification. For optimal feature subset selection, bagging without replacement with Sequential Forward feature Selection (SFS) was implemented. Ensemble SVM with linear kernel achieved Accuracy of 55.6 %.
Somaya Hashem et al.10 evaluated various Machine Learning techniques for predicting advanced fibrosis for the staging of chronic liver diseases. A dataset comprising of 39,567 patients with chronic hepatitis C were trained on Machine Learning algorithms like ADT, genetic algorithm, particle swarm optimization, and multilinear regression models. Their study also found that Age, platelet count, AST, and albumin were important features for the prediction. The results of ADT predicted the staging with accuracy = 84.4% and ROC = 0.76. Their work suggested that prediction of advanced fibrosis after combining with serum biomarkers yielded non-invasive classification models.
Xinhua Wang et al.11 researched 77 patients from the emergency department and Intensive Care Unit (ICU) of The Second Affiliated Hospital of Wenzhou Medical University between January 2015 and January 2016 for early specific diagnosis and effective evaluation of sepsis. 160 features were reduced to 5 features using the feature combination technique. Their work got an 81.6% recognition rate, 89.57% sensitivity, and 65.77% specificity. The researchers used chaotic fruit fly optimization to improve the performance of the kernel model.
192 individuals from the Clinical Research Centre for Medical Equipment Development (CRCMeD) were studied by Katsufumi Inoue et al.12. They classified whether the recorded signals correspond to healthy subjects or patients with dysphagia by using features extracted from respiratory flow, laryngeal motion, and swallowing sounds. The SVM based model yielded Accuracy of 86.4%, Sensitivity of 67.5% and Specificity of 93.3%.
Q. Zou13 studied 68,994 individuals from the hospital’s physical examination data from Luzhou, China, for predicting diabetes mellitus. Techniques like Principal Component Analysis (PCA) and Minimum Redundancy Maximum Relevance (mRMR) were used to reduce the dimensionality of the feature set. The researcher implemented DT, RF and Neural Network, out of which RF achieved the highest Accuracy equal to 80.84%.
The aim of the examining study done by Miguel Patrícioet al.14was to develop and assess a prediction model for breast cancer. 166 patients from the Gynaecology Department of the University Hospital Centre of Coimbra (CHUC), between 2009 and 2013, who were diagnosed with Breast Cancer, were studied. The Machine Learning model was based on anthropometric data and parameters collected from routine blood analysis. Glucose, Resistin, Age and BMI were important features of breast cancer biomarkers to implement into screening tests. The researchers implemented SVM, LR and RF. The results were Sensitivity [82% to 88%], and Specificity [85% to 90%] and AUC with 95% CI in the range of [0.87, 0.91] were the best for SVM.
36 informative locations on the tibiofemoral cartilage compartment from 3D MR imaging on 100 pairs of knee data and MR images from the Osteoarthritis Initiative (OAI) were studied to see the feasibility of Machine Learning algorithms like ANN, SVM, RF and NB by Yaodong Du et al.15. The measurements of Kellgren and Lawrence (KL) grade, Joint Space Narrowing on Medial compartment (JSM) grade and Joint Space Narrowing on Lateral compartment (JSL) grade provided vivid perspective to measure the progression of knee osteoarthritis disease. Using PCA the 36-dimensional feature set was reduced to an 18-dimensional medial feature set and 18-dimensional lateral feature set. The results obtained were 1) KL Grade: ANN [AUC = 0.761 and F-measure = 0.714]; 2) JSM Grade: [RF AUC = 0.785 and F-measure = 0.743]; 3) JSL Grade: [ANN with AUC = 0.695 and F-measure = 0.796].
Time-stamped vital signs and laboratory values were extracted from 401 patients’ EHR to predict Acute Respiratory Distress Syndrome (ARDS). The researchers NarathipReamaroonet al.16 implemented LR, RF, and SVMs with class-weighted cost functions and uncertain labels to predict ARDS. With the Accuracy = 0.8157 and AUROC =08548 which was highest for SVM with uncertain labels, it suggests the applicability of uncertain labels, as uncertain labels are very common in clinical diagnosis.
The Chronic Kidney Disease (CKD) data set available from the University of California Irvine (UCI) Machine Learning Repository was used by researchers Jiongming Qin et al. 17 to detect CKD. Various Machine Learning algorithms like LR, RF, SVM, k-NN, NB and FFNN were used to develop the Machine Learning Model. An integrated model with a combination of LR and RF by using perceptron achieved the highest Accuracy of 99.83%.

As discussed in this section, it is clear that many machine learning techniques are used for the classification of diseases by using metrics like Accuracy, ROC/AUC, Sensitivity and Specificity. SVMs are the most widely researched techniques that are giving good results for classifying diseases. SVMs work with fewer features, yet are powerful for achieving better results. Table 1 describes various techniques and their implementations in classifying various diseases. This comparative analysis also makes clear that a lot of scopes still exists in exploring other techniques that use bagging and boosting mechanisms.
DISCUSSIONS AND CHALLENGES IN IMPLEMENTING MACHINE LEARNING TECHNIQUES
The privacy of the patients that contribute towards generating the dataset to be used in the Machine Learning model must be maintained by imposing security rules. Proper cleaning and curating of data are required before the use of data in the model. Again, data is available in heterogeneous places like archived medical data, pathological labs, EHRs, electronic prescribing tools and databases from insurances, which makes it very challenging to bring together. Unified data formats must be created that may help to mitigate the problem related to interoperability.
Various clinical record sources, different symptom descriptions, and the possibility of attachment of more than one disease to one clinical record pose many challenges towards the implementation of Machine Learning techniques. Due to the digitization of health care records, many redundant symptoms may be collected. Not all features contribute towards the predictability of the model or to increasing the model performance. How can a significant subset of features be selected from these features is also one of the critical aspects of data modelling and understanding. Current Machine Learning techniques are best suited for binary classification. More sophisticated models that can be abstracted on multi-class or multi-label problems have potential benefits as more than one associated disease may diagnose a patient.
One major challenge is that real-world data might differ altogether from training data. This challenge poses a limitation to the clinical model for classification. A prospective model, possessing intelligence to challenge unseen data remains obscure. The researchers must include several measures to report and summarize the performance of the Machine Learning Model. The clinicians and the researchers must join hands to reach a consensus for a common understanding of generated results. Many research papers do not attempt to present such information. As an essential implementation aspect, a relatable workflow model should be created for the practising clinicians that can support the diagnostic process. Machine Learning techniques are developed on a long history of research in traditional medical science and have an encoding of the semantics of medical data. This use of ontologies guiding the learning process may permit human experts to understand and retrace decision processes more effectively.
CONCLUSIONS AND PERSPECTIVES FOR FUTURE WORK
The review encompasses various diseases that are predicted using Machine Learning techniques. These classification problems contribute towards solving traditional classification problems in the context of biomedical and clinical applications. There always exists a level of uncertainty while diagnosing diseases. The diagnosis label can be used as the classification label or predictive outcome for a Machine Learning task. The review suggests that diagnostic uncertainty can be supported by Machine Learning techniques in labelling many diseases. Various algorithms like RF, NB, SVMs, DT and NN can have possible implications to classify other medical diseases in actual clinical diagnosis in future as well.
Deep Neural Networks (DNN) have the potential to benefit a wide range of biological research applications including annotation, semantic linking, and even interpretation of complex biological data in areas including biomarker development, drug discovery, drug repurposing, and clinical recommendations. Researchers can study DNN concerning traditional machine learning methods to deliver substantial improvements. The increased collaboration between researchers in computing and biological studies will have promising advancements towards the applicability of Machine Learning algorithms and techniques for advanced healthcare systems.
ACKNOWLEDGEMENT
The authors acknowledge the immense help received from the scholars whose articles are cited and included in references of this manuscript. The authors are also grateful to authors/editors/publishers of all those articles, journals and books from where the literature for this article has been reviewed and discussed.
CONFLICT OF INTEREST
Authors declare no conflict of interest with anyone.
SOURCE OF FUNDING
No external agencies are involved in funding the work.
AUTHOR’S CONTRIBUTION
Author 1 contributed towards conceptual study, analysis and drafting of the manuscript. Author 2 performed the critical revision of the article.
References:
|
1.
|
Wei L, Yang Y, Nishikawa RM, Jiang Y. A study on several machine-learning methods for classification of malignant and benign clustered microcalcifications. IEEE Trans Med Imaging. 2005;24(2):371–80.
|
|
2.
|
Q. L, C. R, G.D. C. Ventricular fibrillation and tachycardia classification using a machine learning approach. IEEE Trans Biomed Eng [Internet]. 2014;61(6):1607–13. Available from: http://www.embase.com/search/results subaction=viewrecord&from=export&id=L373143052%0Ahttp://dx.doi.org/10.1109/TBME.2013.2275000
|
|
3.
|
Lee BJ, Kim JY. Identification of the Best Anthropometric Predictors of Serum High- and Low-Density Lipoproteins Using Machine Learning. IEEE J Biomed Heal Informatics. 2015;19(5):1747–56.
|
|
4.
|
Melendez J, Van Ginneken B, Maduskar P, Philipsen RHHM, Ayles H, Sánchez CI et al. On Combining Multiple-Instance Learning and Active Learning for Computer-Aided Detection of Tuberculosis. IEEE Trans Med Imaging. 2016;35(4):1013–24.
|
|
5.
|
B.J. L, J.Y. K. Identification of Type 2 Diabetes Risk Factors Using Phenotypes Consisting of Anthropometry and Triglycerides based on Machine Learning. IEEE J Biomed Heal informatics. 2016;20(1):39–46.
|
|
6.
|
Alickovic E, Subasi A. Medical Decision Support System for Diagnosis of Heart Arrhythmia using DWT and Random Forests Classifier. J Med Syst. 2016;40(4):1–12.
|
|
7.
|
Masetic Z, Subasi A. Congestive heart failure detection using random forest classifier. Comput Methods Programs Biomed. 2016;130:54–64.
|
|
8.
|
Kate RJ, Perez RM, Mazumdar D, Pasupathy KS, Nilakantan V. Prediction and detection models for acute kidney injury in hospitalized older adults. BMC Med Inform DecisMak. 2016;16(1).
|
|
9.
|
Sørensen L, Nielsen M. Ensemble support vector machine classification of dementia using structural MRI and mini-mental state examination. J Neurosci Methods. 2018;302:66–74.
|
|
10.
|
Hashem S, Esmat G, Elakel W, Habashy S, Raouf SA, ElHefnawi M, et al. Comparison of Machine Learning Approaches for Prediction of Advanced Liver Fibrosis in Chronic Hepatitis C Patients. IEEE/ACM Trans ComputBiolBioinforma. 2018;15(3):861–8.
|
|
11.
|
Wang X, Wang Z, Weng J, Wen C, Chen H, Wang X. et al. A New Effective Machine Learning Framework for Sepsis Diagnosis. IEEE Access. 2018;6:48300–10.
|
|
12.
|
Inoue K, Yoshioka M, Yagi N, Nagami S, Oku Y. Using machine learning and a combination of respiratory flow, laryngeal motion, and swallowing sounds to classify safe and unsafe swallowing. IEEE Trans Biomed Eng. 2018;65(11):2529–41.
|
|
13.
|
Zou Q, Qu K, Luo Y, Yin D, Ju Y, Tang H. Predicting Diabetes Mellitus With Machine Learning Techniques. Front Genet. 2018;9.
|
|
14.
|
Patrício M, Pereira J, Crisóstomo J, Matafome P, Gomes M, Seiça R, et al. Using Resistin, glucose, age and BMI to predict the presence of breast cancer. BMC Cancer. 2018;18(1).
|
|
15.
|
Y. D, R. A, J. S, M. Z. A Novel Method to Predict Knee Osteoarthritis Progression on MRI Using Machine Learning Methods. IEEE Trans Nanobioscience [Internet]. 2018;17(3):228–36. Available from: http://www.embase.com/search/results?subaction=viewrecord&from=export&id=L625919116%0Ahttp://dx.doi.org/10.1109/TNB.2018.2840082
|
|
16.
|
Reamaroon N, Sjoding MW, Lin K, Iwashyna TJ, Najarian K. Accounting for label uncertainty in machine learning for detection of acute respiratory distress syndrome. IEEE J Biomed Heal Informatics. 2019;23(1):407–15.
|
|
17.
|
Qin J, Chen L, Liu Y, Liu C, Feng C, Chen B. A machine learning methodology for diagnosing chronic kidney disease. IEEE Access. 2020;8:20991–1002.
|
|
18.
|
Rumelhart DE, Hinton GE, Williams RJ. Learning Internal Representations by Error Propagation. Readings CognSci A Perspect from PsycholArtifIntell. 2013;399–421.
|
|
19.
|
C. Cortes and V. Vapnik. Support-Vector Networks. Mach. Learn., vol. 297, pp. 273–297, 1995.
|
|
20.
|
Breiman L. Random Forests. Mach. Learn., vol. 4, pp. 5–32, 2001.
|
|
21.
|
1. Hand DJ, Yu K. Idiot’s Bayes: Not So Stupid after All? Int Stat Rev / Rev Int Stat. 2001;69(3):385.
|
|
22.
|
Leo Breiman, Jerome H Friedman, Richard A Olshen, Charles J Stone, Classification and regression tree Monterey, CA: Wadsworth & Brooks/Cole Advanced Books & Software. 1984.
|
|
23.
|
https://www.cs.waikato.ac.nz/ml/weka/
|
|
24.
|
Gupta D, Khare S, Aggarwal A. A method to predict diagnostic codes for chronic diseases using machine learning techniques. Proceeding - IEEE IntConfComputCommunAutom ICCCA 2016. 2017;281–7.
|
|
25.
|
Du L, Xia C, Deng Z, Lu G, Xia S, Ma J. A machine learning based approach to identify protected health information in Chinese clinical text. Int J Med Inform. 2018;116:24–32.
|
 IJCRR
IJCRR 





 This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License





