IJCRR - 13(7), April, 2021
Pages: 196-203
Date of Publication: 12-Apr-2021
Print Article
Download XML Download PDF
A Succinct Analysis for Deep Learning in Deep Vision and its Applications
Author: Preethi N, W. Jai Singh
Category: Healthcare
Abstract:Introduction: Deep learning methodologies can achieve forefront results on testing deep vision issues, for instance, picture portrayal, object area, face affirmation, Natural Language Processing, Visual Data Processing and online life examination. Con�vNet, Stochastic Hopfield network with hidden units, generative graphical model and sort of artificial neural network castoff to absorb competent information coding in an unproven way are deep learning plans used in deep vision issues. Objection: This paper gives a succinct survey of without a doubt the most critical Deep learning structures. Deep vision assign�ments, for instance, object revelation, face affirmation, Natural Language Processing, Visual Data Processing, web-based life examination and their utilization of this task are discussed with a short record of the historic structure, central focuses and impairiments. Future headings in arranging Deep learning structures for Deep vision issues and the troubles included are analysed. Method: This paper consists of surveys. In Section two, Deep Learning Approaches and Changes are audited. In section three, we tend to portray the uses of Applications of deep learning in deep vision. In Section four, Deep learning challenges and directions are mentioned. At long last, Section five completes the paper with an outline of the results. Conclusion: Though deep learning can recall a huge proportion of data and info, it's feeble cognitive and perception of the data makes it a disclosure answer for certain applications. Deep learning despite everything encounters issues in showing various erratic facts modalities at the equal period. Multimodal profound learning is an extra notable heading in progressing deep learn�ing research.
Keywords: ConvNet, Stochastic Hopfield network, Generative graphical model, Social media analysis, Data processing, Deep Learning
Full Text:
Deep vision is an integrative intelligent arena that oversees in what way deep tin be ended to build raised equal appreciation since deep pictures or chronicles. Since the viewpoint of building, it attempts to deep endeavours that the hominidgraphic structure tin do.1-3 Deep learning grants machine models of various taking care of layers to be told and address knowledge with various degrees of reflection addressing however the neural structure sees and grasps multimodal data, as needs are unquestionably getting included structures of colossal extension data. What perceived deep vision from the basic field of cutting edge picture getting ready around then remained a yearning toward isolate three-D structure after pictures by the area of accomplishing complete act thoughtful. Training during the 1970s moulded the initial basic aimed at countless the deep vision figuring that happen nowadays, as well as withdrawal of limits as of pictures, naming of appearances, non-polyhedral and polyhedral illustrating, depiction of articles as inter associates of humbler constructions, visual stream, and development approximation.4 The desire to form a structure that reproduces the human brain drove the elemental progression of neural frameworks. In 1943, McCulloch and Pitts5 endeavoured toward realizing however the neural structure might create uncommonly complicated models by victimization organized developed cells, known as neurons. The McCulloch and Pitts prototypical of a vegetative cell, known as an MCP prototypical, has created a vital duty toward the advance of pretending neural frameworks.
Deep learning has drove fantastic strolls in briefing of computer vision complications, let's say, entity identification, movement following, activity acknowledgment, human skill estimation, and linguistics division.6-15 During this arrangement, we'll minimalistically evaluation the core progressions in deep learning models besides figuring for computer vision bids during the extraordinary circumstance, Three of the foremost vast sorts of deep learning prototypical with relevancy their significance in visual kind, that is, ConvNet, the "Boltzmann special" composed with Deep Belief Networks (DBNs) and Deep Boltzmann Machines (DBMs) and Stacked (Denoising) Autoencoders.
This paper consists of surveys. In Section two, Deep Learning Approaches and Changes are audited. In section three, we tend to portray the uses of Applications of deep learning in deep vision. In Section four, Deep learning challenges and directions are mentioned. At long last, Section five completes the paper with an outline of the results.
DEEP LEARNING APPROACHES AND CHANGES
ConvNet
ConvNetvictimization the boner incline and accomplishing usually astounding ends up in a briefing of model affirmation tasks.16-18 ConvNet is spurred by the visual scheme sassembled, and expressly through its prototype planned in.19 The principle machine prototype dependent on procurable systems among neurons and logically created changes out of the copy are create inNeocognitron20, which delineates that once neurons through comparative limits are suitable on areas of the past pane by completely dissimilar zones, a method of change of location in vacillation is secured.
A CNN incorporates 3 commonplace forms of neural layers, to be express, (a) ConvNet Phase, (b) combining layers, and (c) whole Merging layers. Variety of phase settle for substitute activity. (Figure1) shows a CNN building for a piece characteristic proof in copy mission. Each phase of a ConvNet changes info capacity to a yield capacity of somatic cell commencement, over the long-term agitative the last whole connected layers, achieving a mapping of the info to a 1D embody vector. CNN's are exceptionally productive in deep vision applications, to Illustrate, face affirmation, object revelation, driving idea to apply autonomy vehicles.
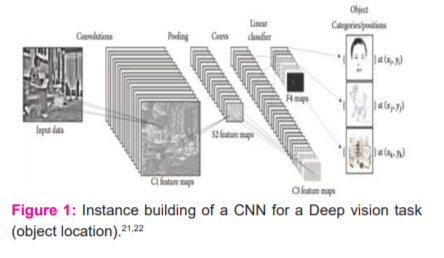
(a) ConvNetPhase: Conv Net Phase, a Conv Net uses numerous bits to rotate the entire copy similarly to the midway component maps, delivering diverse component plots. As the advantages of the complication action, a couple of task 21,22have planned it as an additional for totally associated phase through the ultimate objective of achieving speedier learning events.
(b) Combining Phase: Combining Phaseremainin charge of diminishing the three-dimensional estimations of the data capacity aimed at the following difficult phase. The combining phase doesn't impact the significance estimation of the capacity. This action achieved through this lateral indicated sub examining or down testing, by way of the diminishing of scope prompts a concurrent lack of evidence. In any case, mishap may be helpfully aimed at the framework because the decline in dimensions prompts fewer figures overhead used for the future phases of the framework, also besides that kills overflow. Typical combing and max combining are the maxima generally applied procedures. Distinct academic examination of max combining and ordinary combining shows is assumed, and exhibited the most extreme combing could provoke speedier intermixing, select dominating constant structures, and upgrade hypothesis.23,24 Different various assortments of the combining phase of the composition, inspired through changed motivation sand helping indisputable necessities.
c) Completely Linked Layers. Following one or two complexity and combining phase, large phase intuition within the neural framework is achieved by strategies for wholly associated phase. Neurons in an exceedingly wholly associated phase take complete relationship with completely sanctionative within past phase, as per their tag recommends. In the beginning, this point forward is non-commissioned with a structured growth followed by an inclination offset. wholly associated phase ineluctably change the 2nd article plots into a 1D embrace path. The result and path moreover may well remain addressed advancing to selected ranging orders used for game set up or might remain thought-about as per a path for additional method.25,26 ConvNet structure uses three strong attention: (a) area responsive range, (b) fixed burdens, and (c) Structural subsample. Taking into account close by responsive range, every component in a convolutional layer gets ideas of neighbouring components having a spot with the last layer. Thusly neurons are fit for removing simple visual features, for instance, boundaries or joints. The above-mentioned selections are formerly joined through the following complex phases acknowledge complex solicitation structures. Plus, straight forward part locators, that are helpful on a touch of a picture, are presumptively attending to be vital over the complete figure is ample through the chance of joint burdens. The joint burdens goal is a good deal of items toward own vague burdens. Decidedly, the elements of a convolutional layer sifted through sphere. Entireelementsset up supply a comparable game plan of burdens. Hence, every plane is in danger for building a selected part. The yields of the sphere are known as structural plots. Every convolutional layer involves one or two of planes,thus varied phase maps is created at every region. throughout the advancement on the part plot, these complete figures are checked through elements that are taken care of at staring at regions within the phase maps. This improvement is like a convolution action, trailed by an extra substance tendency period and sigmoid edge:
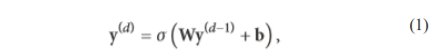
Here ???? states the importance of the convolutional layer, the weight cross-section is denoted by W, and the inclination term is denoted by b. Completely associated neural frameworks, burden lattice is filled, that is, interfaces all commitment to the respective element through totally unlike burdens. For ConvNet, W is the burden system which is too little visible of the chance of tied burdens. Consequently, the kind of W has
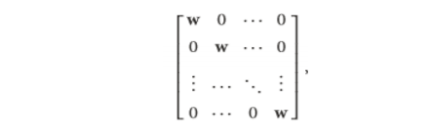
Here w is matrices taking comparative estimations with the units' open fields. victimisation associate inadequate weight matrix diminishes the quantity of the framework's tunable parameters and thus grows its theory limit. increasing W with layer inputs takes once convolving the commitment with w, which might be seen as a trainable channel. If the commitment to ????−1convolutional layer is of estimation ????×???? and therefore the responsive field of units at a particular plane of convolutional layer ???? is of estimation ????×????, by then the created element guide is going to be a structure of estimations (????−????+1)×(????−????+1). Precisely, the phase of feature plot at(????,????) tract is going to be
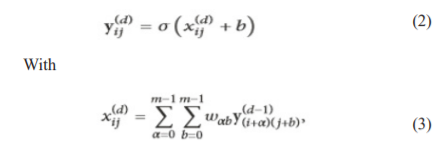
Here the scalar b. Using (2) and (3) consecutively for entirely (????,????) spots of knowledge, the half plot for the relating plane is made.
The difficulties which will develop by preparing of CNNs needs to fix with the tremendous variety of strictures which has got acknowledged, that can incite the effort by overfitting. to the present finish, frameworks, maybe, random pooling, dropout, and information development are planned. additionally, CNNs are as typically as attainable assumed to pre-processing, which is, a technique that instates the framework by pre-processing parameters as hostile without aim set ones. Pretraining will enliven the educational technique and update the hypothesis limit of the framework. All things thought-about, CNNs were looked as if it would primarily trump commonplace AI methods is a very wide extent of Deep vision and model affirmation errands32, samples are given in Section3. Its splendid show got alongside the relative simplicity in preparing are the essential reasons that specify the unfathomable arrive of their predominance in the course of the most recent number of years.
Generative graphical model and Stochastic Hopfield network with hidden units
Deep Belief Networks and Deep Boltzmann Machines are Deep learning models that belong to the "Boltzmann family," as they utilize the Restricted Boltzmann Machine (RBM) as a knowledge module. The generative stochastic artificial neural network is also called the Restricted Boltzmann Machine (RBM). DBNs have an objectiveless relationship by two layers that structure an RBM and guiding relationship with the lesser layers. The generative graphical model has a directionless association among the full layers of the framework. An apt representation of DBNs and DBMS can be initiate in (Figure2). In going with subclasses, we will depict the major characteristics of DBNs and DBMs, in the wake of presenting their fundamental structure hinder, the RBM.
Generative graphical model
Deep Belief Networks (DBNs) are probabilistic generative models that provide a probability transport ended perceptible information and also names. That is shaped by loading RBMs and setting them up in a covetous way, that are planned in.27 A DBN from the start uses a helpful layer-by-layer energetic knowledge procedure to gift many frameworks, and, within the facet project, adjusts all plenty in conjunction with the right yields. DBNs are graphical models that add up the way to evacuate a big dynamic depiction of the readiness information. They model the be a part of t spread between watched vector x and also the ???? lined layers h???? as follows:
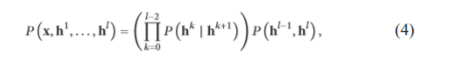
where x =h0,????(h???? |h????+1)is Associate in Nursing unforeseen alternative aimed at the perceptible components at level ???? adjusted arranged the lined components of the RBM at equal????+1, and ????(h????−1|h????) remains that the taken for granted - lined joint unfold within the top-ranking RBM.
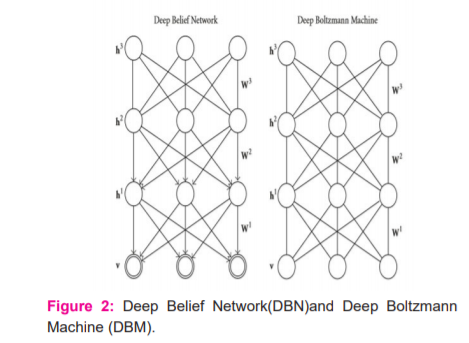
The top two layers of a DBN structure a directionless outline n and the remainder of the layers structure a conviction facilitate by composed, top-down affiliations. In a DBM, all affiliations are directionless.
The standard of m voracious layer-wise freelance coming up with is functional to DBNs by RBMs because the structure frustrates for every layer.28 A summary portrayal of the system is as follows:
(1) Train the chief layer as an RBM which models the rough info x=h0 as its perceptible layer.
(2) Practice that 1st layer to secure an outline of the info which may be used as data for the following layer. 2 typical game plans exist. This depiction is picked just like the mean authorization (h1=1|h0) or trial of (h1|h0).
(3) Train the second layer as an RBM, which modified information (tests or mean commencement) as coming up with examples(for the conspicuous layer of that RBM).
(4) Restate steps ((2)and(3)) for the right variety of layers, whenever multiplying upward either test or mean characteristics.
(5) Fine-tune all the limits of this vital structure with relevancy a middle person for the DBN log-likelihood, or concerning a regulated coming up with live (consequent to adding further learning device to vary over the perceptive depiction into oversaw gauges, e.g., an instantaneous classifier).
There are 2 essential inclinations within the above-depicted unsatiable learning methodology of the DBNs.29 First, it handles the trial of acceptable assurance of parameters, that once during a whereas will incite poor within reach optima, as desires are guaranteeing that the framework is befittingly conferred. Second, there's no essential for checked information since the system is freelance. Regardless, DBNs are in a like manner full of totally different deficiencies, parenthetically, the procedure value connected with putting in a DBN and also the manner that the strategies towards any improvement of the framework dependent on most outrageous chance preparing gauge are cloudy.28 to boot, a very important obstruction of DBNs is that they don't speak to the 2D structure of an information image, which can primarily impact the show and connection in deep vision and sight and sound examination problems. Regardless, a later assortment of the DBN, the CDBN is a generative graphical model, uses the three-dimensional info of neighbouring pixels by presenting convolutional RBMs, afterwards creating a change invariant generative model that with success scales with relevancy high dimensional photos.30
APPLICATIONS OF DEEP LEARNING IN DEEP VISION
These days, employments of Deep learning join anyway are not obliged to NLP (e.g., sentence gathering, translation, etc.), visual data dealing with (e.g., Deep vision, blended media data assessment, etc.), talk and sound getting ready (e.g., overhaul, affirmation, etc.), relational association examination, and restorative administrations. This portion offers nuances to the unrelated techniques used for the respective application.
Natural Language Processing
NLP is a movement of estimations and frameworks that essentially based on demonstrating deep to fathom the human language. NLP endeavours fuse report portrayal, understanding, revise recognizing confirmation, content closeness, summary, and question answering. NLP progression is attempting a direct result of the multifaceted nature and unsure building of the human language. Furthermore, ordinary language is significantly setting express, where severe ramifications change subject to the kind of words, joke, and region distinction. Significant learning systems have starting late had the choice to show a couple of compelling undertakings in attaining high precision in NLP errands.
Most NLP models follow a practically identical pre-planning step: (1) the information content is isolated into words by tokenization and a while later (2) these words are rehashed as vectors or n-grams. Addressing words in a low estimation is fundamental to make a precise perspective on similarities and differentiation among numerous words. The test shows up when there is essential to pick the length of words limited in each n-gram. This strategy is setting express and needs previous region data. A part of the outstandingly noteworthy systems in appreciating the most prominent NLP assignments are presented underneath.
Sentiment Analysis
This bit of NLP supervises looking at a book and organizing the propensity or evaluation of the author. Maximum datasets for end assessment are separate as either confident or undesirable, and reasonable enunciations are expelled by bias demand philosophies. The single commended model is the Standford Sentiment Treebank (SST)31, a dataset of film surveys set apart into five classes (going from negative to unfathomably positive). Near to the preface to SST, Socher et al.31 propose a Recursive Neural Tensor Network (RNTN) that usages word vectors and parses a tree to address an enunciation, getting the coordinated efforts among the parts with a tensor-based strategy work. This recursive methodology is perfect concerning sentence-level depiction since the emphasis reliably shows a tree-like structure.
Kim32 improves the correctness for SST by next a substitute technique. Notwithstanding the way that CNN models were first made considering picture insistence and strategy, their execution in NLP has displayed to be a triumph, accomplishing brilliant outcomes. Kim grants a direct CNN model utilizing one convolution layer on masterminded word2vec vectors in a BoW structure. The representations were spared sensibly crucial with relatively few hyperparameters for change. By a mix of low tuning and pretrained task-express parameters, they understand how to accomplish high precision on two or three standards. Online life is a prominent wellspring of information while dissecting notions.
Machine Translation
Deep learning has accepted a noteworthy activity in the updates of customary customized translation systems. Cho et al.33 presented a new RNN-based encoding and unwinding configuration to set up the words in a Neural Machine Translation (NMT). The RNN Encoder-Decoder framework practices two RNNs: one plots a data progression into fixed-length vectors, however, the other RNN translates the vector into the goal pictures. The problem with the RNN Encoder-Decoder is the introduction fall as the data course of action of pictures extends. Bahdanau et al.29 address this question by introducing a dynamic-length vector and by together knowledge the alter and disentangle techniques. Their approach is to play out a matched mission to scan for syntactic structures that are commonly judicious for understanding. In any case, the starting late planned translation schemes are known to be computationally classy and incompetent in dealing with sentences covering unprecedented words.
Paraphrase Identification
Rework distinguishing proof is the path toward separating two sentences and foreseeing how equivalent they rely upon their essential covered semantics. A key part which is useful for a couple of NLP occupations, for instance, copyright encroachment acknowledgment, answers to questions, setting area, abstract, and region recognizing evidence. Socher et al.34 suggest the usage of spreading out Recursive Autoencoders (RAEs) to amount the resemblance of two sentences. Using syntactic trees to progress the part space, they measure both word-and articulation level comparable qualities. Notwithstanding the way that it is on a very basic level equivalent to RvNN, RAE is useful in independent request. Not in the slightest degree like RvNN, RAE registers a generation screw up in its place of a controlled score during the meeting of two vectors into a compositional vector. This article furthermore introduced a dynamic pooling layer that can consider and bunch two sentences of unlike sizes as either a translation or not.
Visual Data Processing
Deep learning techniques have developed the central bits of numerous front line intelligent media systems and Deep vision.35 Even more unequivocally, CNNs have exhibited basic results in different genuine endeavours, including picture taking care of, object acknowledgement, and video getting ready. This zone discusses more bits of knowledge concerning the most recent significant learning structures and estimations planned over the late years for visual data taking care of.
Image Classification
In 1998, LeCun et al. prevailing the essential type of LeNet-5.36 LeNet-5 is a standard CNN that joins two convolutional layers close by a subselection layer ultimately getting done through a complete relationship in the previous layer. Despite the way that, since the mid-2000s, LeNet-5 and other CNN strategies were hugely used in dissimilar issues, counting the division, area, and portrayal of pictures, they were nearly rejected by data mining and AI study get-togethers. Over a multi decade later, the CNN figuring has started its thriving in Deep vision systems. Exactly, AlexNet is seen as the first CNN prototype that significantly enhanced the image portrayal consequences on an amazingly colossal dataset (e.g., ImageNet). It was the victor of the ILSVRC 2012 and improved the best results from the prior years by for all intents and purposes 10% concerning the best five test bumble. To recover the effectiveness and the rapidity of setting up, a GPU execution of the CNN is used in this framework. Data increment and dropout methods are furthermore used to altogether lessen the overfitting issue.
Object Detection and Semantic Segmentation
Deep learning methodology accepts a noteworthy activity in the movement of article distinguishing proof starting late. Before that, the best article acknowledgement execution began from complex structures with a couple of low-level structures (e.g., SIFT, HOG, etc.) and huge level settings. In any case, with the methodology of new significant learning frameworks, object ID has in like manner showed up at another period of progress. These advances are driven by compelling methodologies, for instance, zone recommendation and section-based CNN (R-CNN).37 R-CNN defeats any obstruction among the article area and picture game plan by presenting section grounded thing repression strategies using deep frameworks. Besides, the move to learn and relating on a colossal dataset (e.g., ImageNet) is applied since the little thing acknowledgement datasets (e.g., PASCAL [46]) fuse lacking named data to set up a gigantic CNN sort out. In any case, in R-CNN, the readiness computational time and memory are over the top costly, particularly on novel ultra-significant frameworks (e.g., VGGNet).
Video Processing
Video examination has pulled in broad thought in the deep vision organize and is measured as a troublesome task since it consolidates mutually spatial and brief data. In an early slog, colossal degree YouTube accounts containing 487 game classes are used to set up a CNN model. The model fuses a multiresolution designing that employs the close-by development data in accounts and joins setting stream (for low-objectives picture illustrating) and fovea stream (for significant standards picture dealing with) modules to arrange chronicles. An occasion acknowledgement from game chronicles using significant learning is presented in.38 In that work, both spatial and brief data are determined using CNNs and feature mix through standardized Autoencoders. Starting late, another framework called Recurrent Convolution Networks (RCNs)39 was introduced for video dealing. It smears CNNs on video traces for pictorial comprehension and a short time later deals with the housings to RNNs for exploring transient information in accounts.
Social Media Analysis
Social Web Analysis
The notoriety of various relational associations like Facebook and Twitter has engaged customers to part a ton of data with their photographs, considerations, and sentiments. Because of the way that significant knowledge has revealed hopeful execution on visual data and NLP, unmistakable significant learning methods have been grasped for relational association examination, including semantic evaluation, interface estimate, and crisis response.40-42 Semantic appraisal is a huge field in casual association assessment, which means helping machines with understanding the semantic significance of posts in relational associations. Though a collection of techniques have been planned to separate works in NLP, these strategies might disregard addressing a couple of standard difficulties in relational association assessment, for instance, spelling botches, abbreviated structures, unprecedented characters, and easy-going vernaculars.43
Twitter can be considered as the most routinely used wellspring of appraisal request for relational association examination. Generally speaking, feeling examination hopes to choose the mien of analysts. Consequently, SemEval has given a standard dataset reliant on Twitter and run the assessment game plan task since 2013.44 Another practically identical model is Amazon, which ongoing as an online book shop and is as of now the world's greatest online retailer. With an abundance of acquirement trades, a colossal proportion of evaluations are made by the clients, making the Amazon dataset a remarkable hotspot for tremendous extension estimation plan.44
Information Retrieval
Deep adapting incredibly influences information recuperation. Deep Structured Semantic Modelling (DSSM) is planned for text recuperation and web search45, where the dormant semantic examination is driven by a DNN and the inquiries nearby the explore data are used to choose the eventual outcomes of the recuperation. The encoded requests and explore data are mapped into 30k-estimation by term hashing and a 128-estimation feature space is delivered by the multilayer nonlinear plans. The proposed DNN is set up to interface the offered inquiries to their semantic criticalness with the help of the explore data. Regardless, this proposed classical treats each term autonomously and disregards the relationship among the terms.
DEEP LEARNING CHALLENGES AND DIRECTIONS
With the extraordinary progression in profound learning and its assessment scenes existence at the centre of attention, profound learning has expanded excellent power in talk, language, and visual revelation structures. In any case, a couple of spaces are still faultless by DNNs owing to either their troublesome countryside or the nonattendance of data openness for the overall populace. This makes important possibilities and productive ground for compensating upcoming study streets.
The most significant future AI issues won't have sufficient getting ready tests with names.46 Beside the zettabytes of starting at now open data, petabytes of data are incorporated every day. This exponential improvement is gathering data that can never be named by human aid. he current estimation is pleasing to coordinated learning, by and large by the immediately open imprints and the little sizes of current datasets. Regardless, with the brisk augmentations in the scope and unpredictability of information, independent learning will be the predominant course of action later on. Current profound learning models will in like manner need to conform to the rising issues, for instance, data sparsity, missing data, and disordered data to get the approached info over discernments as opposed to getting ready.
Another achievement challenge looked by profound learning techniques is the decline of dimensionality without losing fundamental information required for request. In clinical applications like danger RNA sequencing examination, generally, the amount of tests in each imprint is far not the number of features. In current profound learning models, this causes outrageous overfitting issues and limits the fitting course of action of lacking cases.
Current profound learning structures require broad proportions of computational advantages for the push toward the front line presentations. One system attempts to vanquish this test by using store preparing. Added different is to custom the slow systems that misuse medium and colossal datasets on separated getting ready. In rhythmic movement years, various researchers have moved fixation to develop equivalent and versatile profound learning frameworks.
CONCLUSION
Deep learning, another and fervently discussed issue in AI, can be described as a course of layers acting nonlinear getting ready to get comfortable with various degrees of data depictions. This article contemplates the top tier counts and methods in deep learning. A couple of disclosures of this article and likely future work are dense underneath:
• Thoughdeep learning can recall a huge proportion of data and info, its feeble cognitive and perception of the data makes it a disclosure answer for certain applications. The interpretability of deep learning should be inspected later on.
• Deep learning despite everything encounters issues in showing various erratic facts modalities at the equalperiod. Multimodal profound learning is extra notable heading in progressing deep learning research.
• Disparate human personalities, deep adapting needs wide datasets (unmistakably named data) for coming down the machine and anticipating the inconspicuous information. This issue turns out to be all the more overwhelming when the existing datasets are pretty much nothing (e.g., social protection data) or when the data ought to be arranged ceaselessly. One-shot learning and zero-shot learning have been packed in the continuous hardly any years to help this issue.
• In disdain of all the profound learning types of progress starting late, various applications are up 'til now flawless by profound learning or are first and foremost times of using the profound learning systems (e.g., disaster information the load up, cash, or clinical data assessment).
References:
-
Ballard DH, Brown CM. Deep Vision. Prentice-Hall, 1982 .
-
Vandoni HT, Carlo E. Deep Vision : Evolution and Promise (PDF). CERN :21–25.
-
Sonka M, Hlavac V, Boyle R. Image Processing, Analysis, and Machine Vision. Thomson, 2008.
-
Szeliski R. Deep Vision: Algorithms and Applications. Springer Science & Business Media 2010:10–16.
-
McCulloch WS, Pitts W. A logical calculus of the ideas immanent in nervousactivity. Bull Math Biol 1943;5(3):115–133.
-
Ouyang W, Zeng X, Wang X. Deep ID-Net: Object Detection with Deformable Part Based Convolutional Neural Networks. IEEE Transact Pattern Anal Machine Intel 2017;39(7):1320–1334.
-
Diba A, Sharma V, Pazandeh A, Pirsiavash H, Gool LV. Weakly Supervised Cascaded Convolutional Networks. 2017:5131–5139.
-
Doulamis N, Voulodimos A. FAST-MDL: Fast Adaptive Supervised Training of multi-layered deep learning models for consistent object tracking and classification. IEEE International Conference on Imaging Systems and Techniques (IST) 2016:318–323.
-
Doulamis N. Adaptable deep learning structures for object labelling /tracking under dynamic visual environments. Multimedia Tools and Applications 2017;1–39.
-
Lin L, Wang K, Zuo W, Wang M, Luo J, Zhang L. A deep structured model with radius-margin bound for 3D human activity recognition. 2016: arXiv:1512.01642.
-
Cao S. Exploring deep learning-based solutions in fine grained activity recognition in the wild. 23rd International Conference on Pattern Recognition (ICPR) 2016:384–389.
-
Toshev T, Zegedy CS. Deep Pose: Human pose estimation via deep neural networks. 2014:arXiv:1312.4659.
-
Chen X, Yuille XL. Articulated pose estimation by a graphical model with image dependent pairwise relations. 2014: arXiv:1407.3399
-
Noh H, Hong S, Han B. Learning deconvolution network for semantic segmentation. 2015: arXiv:1505.04366.
-
Long J. Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. 2015: arXiv:1411.4038.
-
LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998:2278–2323.
-
LeCun Y, Boser B, Denkeretal JS. Back propagation applied to hand written zipcode recognition. Neural Comp 1989;1(4):541–551.
-
Tygert M, Bruna J, Chintala S, LeCun Y. A mathematical motivation for complex-valued convolutional networks. Neural Comp 2016;28(5):815–825.
-
Hubel DH, Wiesel TN. Receptive fields, binocular interaction, and functional architecture in the cat’s visual cortex. J Physiol 1962;160(1):106–154.
-
Fukushima K. Neo cognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol Cybern 1980;36(4):193-202.
-
Oquab M, Bottou L, Laptev I, Sivic J. Is object localization for free?-Weakly-supervised learning with convolutional neural networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2015:685– 694.
-
Szegedy C, Liu W, Jia Y. Going deeper with convolutions. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2015:1–9.
-
Boureau YL, Ponce J, LeCun Y. A theoretical analysis of feature pooling invisual
recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2010.
-
Scherer D, Muller A, Behnke S. Evaluation of pooling operations in convolutional architectures for object recognition. 20th International Conference on Artificial Neural Networks (ICANN), Thessaloniki, Greece, September 2010:92–101.
25. Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with Deep convolutional neural networks. 2012:1097–1105. ImageNet Classification with Deep Convolutional Neural Networks (nips.cc)
26. Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv:1311.2524v5.
27. Hinton GE, Salakhut RR. Reducing the dimensionality of data with neural networks. Science 2006;313(5786):504–507.
28. Bengio Y, Courville A, Vincent P. Representation learning: a review and new perspectives. arXiv:1206.5538.
29. Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. arXiv:1409.0473.
30. Lee H, Grosse R, Ranganath R, Ng AY. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. 2009;12:609–616.
31. Socher R, Perelygin A. Recursive deep models for semantic compositionality over a sentiment treebank. Conference on Empirical Methods in Natural Language Processing 2013:1631–1642.
32. Kim Y. Convolutional neural networks for sentence classification. arXiv:1408.5882.
33. Cho K, van Merrienboer B. Learning phrase representations using RNN encoder-decoder for statistical machine translation. 2014. arXiv:1406.1078.
34. Huang GB, Lee H, Learned-Miller E. Learning hierarchical representations for face verification with convolutional deep belief networks. 2012. IEEE Conference on Computer Vision and Pattern Recognition
35. Ha HY, Yang Y. Correlation-based deep learning for multimedia semantic concept detection. International Conference on Web Information Systems Engineering 2015:473–487.
36. LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition 1998; Proceedings of the IEEE 86(11):2278 - 2324.
37. Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. 2014: arXiv:1311.2524
38. Siddarth G, Nanjundan P. An Analysis of Machine Learning Algorithms in Profound. Eur J Mol Clin Med 2020;7(2):5179-5192.
39. Donahue J, Hendricks LA. Long-term recurrent convolutional networks for visual recognition and description. 2015. arXiv:1411.4389.
40. Vosoughi S, Raghavan PV, Roy D. Tweet2Vec: learning Tweet embeddings using character-level CNN-LSTM encoder-decoder. 2016: arXiv:1607.07514.
41. Liu F, Liu B, Sun C, Liu M, Wang X. Deep belief network-based approaches for link prediction in signed social networks. Entropy 2015;17(4):2140–2169.
42. Dat Tien Nguyen, Shafiq R. Joty, Muhammad Imran, et al , Applications of online deep learning for crisis response using social media information 2016. arXiv:1610.01030.
43. Preslav Nakov, Alan Ritter, Sara Rosenthal. SemEval-2016 Task 4: Sentiment Analysis in Twitter. ACL Anthology 2016:1–18.
44. Zhang X, Zhao J, LeCun Y. Character-level convolutional networks for text classification. 2015: arXiv:1509.01626.
45. Huang PS, He X, Gao J. Learning deep structured semantic models for web search using clickthrough data. Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2013:2333–2338.
46. LeCun Y, Bengio Y, Hinton G. Deep learning. Nature 2015;521(7553):436–444.
|
 IJCRR
IJCRR 





 This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License





