IJCRR - 3(10), October, 2011
Pages: 106-113
Print Article
Download XML Download PDF
COMPARISON EFFECTIVENESS OF GROUPCOGNITIVE TRAINING AND LOGO THERAPY IN
DEPRESSED ELDERLY MEN IN RASHT
Author: Shahnam Abolghasemi, Sorourosadat Mousavi, Mohammad Mojtaba Keikhayfarzaneh
Category: Healthcare
Abstract:The main goal of the present research was to compare effectiveness of group-cognitive training and logo
therapy in depressed elderly men in Rasht. In this experimental study participants were all of elderly
men who has been cared in private nursing homes in Rasht in 2009-2010.The research design was in the
form of pretest \?post test and control group and research instrument was depression inventory . All of
participants completed depression inventory .45 of who were high scorers in inventory were selected and
randomly were divided to three groups. The first and second group as experimental group and the third as
control group .The experimental groups had 10 seventy four hours weekly sessions of cognitive and
logo therapy .Again all of the participants completed depression inventory .Treatment data was analyzed
by using ANOVAs covariance analysis . Finding in three groups showed a decrease in depression by
using group_ cognitive method and logo therapy but in comparison the effectiveness of group cognitive
therapy was more than logo therapy.
Keywords: Depression, Elderly men, Cognitive Therapy, Logo Therapy
Full Text:
INTRODUCTION
The limitations of the process mining algorithms such as Heuristic Miner (HM) and the Disjunctive Workflow Schema (DWS) were seen as the need to search for a process model representation that overcomes these limitations. Below it was stated that these limitations and comparison with the association rule mining algorithm LinkRuleMiner (LRM) with the results of HM and DWS mining algorithms. The HM is one of the most robust algorithms available till date for logs containing noise and imbalance. Weijters et al. [1] conducted experiments with the HM on the benchmark artificial material. The result of these experiments emphasized the robustness of the algorithm in situations of noise and imbalance present in the log in various degrees. However the experiments were conducted on artificial material and using the default parameter settings of the algorithm When the algorithm was applied to two dyeing process implementations i.e. Emerald and Jayabala dyeing units, It is identified that the results of the HM are not what the dyers or experts were expecting, hence the alternative process model for the dyeing process need to be identified. Therefore, the association rule mining algorithms were used as a new approach to implement the dyeing industries, dyeing processing system with various association mining algorithms such as Apriori, FPGrowth, HMine and LinkRuleMiner were discussed. The limitation of HM, DWS vs. LRM The purpose of the HM process mining algorithm is to discover the process model underlying the investigated process. Hence, it is performed with many experiments with different parameter settings but the algorithm failed to provide a clear and understandable process model [2]. The process models obtained were complex and full of problems like missing activities (activities registered in the event log but not captured in the process model), missing dependencies and dangling activities. When the dyeing logs were mined without using the all-activities connected heuristic the process model obtained for some logs were better in terms of simplicity. But these models were full of disconnected and dangling activities, and therefore these models do not exhibit those connections that were shown by the models generated using the all-activities connected heuristic parameter. So, it could not be concluded whether not using the all-activities connected heuristic is a good choice. [3]. comparison of HM, DWS process mining algorithms with linkruleminer association rule mining algorithm The LRM however can be compared to the results of the HM as they both generate different process models. The HM generates a dependency graph and the LRM generates association rules. The limitations of the HM therefore are not dealt with in the LRM. The LRM just provides an alternate process model representation different from the one based on the pure control flow. The LRM gives insights into the process but not in form of a visual process model like the Petri nets or the dependency graph. However, these process models can be obtained using the clustered PIs from the LRM using some mining algorithm available in ProM [4] [5]. Our purpose behind the proposal and implementation of the LRM was not to replace the HM but was to obtain behavioural insights into the underlying process. This behaviour is not explicitly presented in a dependency graph. Moreover, it should be noted that the LRM is able to deal with noise if noise refers to the errors done in recording the activities in their proper execution order [6]. As the association rules only represent the associations between the activities purely based on their execution, therefore if any log does not have the ?timestamp‘ information, the association rules would still be consistent. This was observed in the Jayabala dyeing units dyeing process because in this implementation the ?timestamp‘ information of the activities is missing and only the date is recorded [7]. If such logs are given to the HM and the DWS algorithms, they may not be able to generate correct models as the dependency graph will still depict the erroneous dependencies, and also the discriminant rules [8] will portray wrong results. Though the LRM seems to be a good approach for mining flexible processes, it can be improved to provide better results. The next section illustrates the experiment with an example of dyeing process. Comparison between DWS and LRM algorithms: A Case Study To demonstrate the implementation of DWS algorithm in the domain of dyeing process, the three shades dyeing process is taken from Emerald dyeing unit. The three shades dyeing process has 683 PIs, 70 different ATEs and 12,294 total number of ATEs. The cluster log is derived from the DWS process mining algorithm is shown in the figure 1. Then the exported cluster log is given as input to HM algorithm to produce the simplified process model. It is identified that the whole log is very complex to understand than the clustering log. To compare the association rule mining algorithm LRM, the same event log is taken for the study. The Weka library produces the association rules for the given parameter settings as a input. Hence, the LinkRuleMiner (LRM) algorithm produces the same 10 association rules as shown in Figure 2. The LRM algorithm has the effective results with the performance of less memory overhead and high speed. These LRM association rules would help us in obtaining simpler and understandable process models that give meaningful insights into the underlying process. For this experiment the same log as used for DWS is used. As it is know that it has 683 process Instances (PIs), 70 different Event logs and 12,294 total numbers of ATEs are used to illustrate the LinkRuleMiner algorithm. The minimum support for the upper bound is set to 0.7 and the confidence is set to 0.9 to illustrate this algorithm. Hence, the Figure 2 gives the process model generated by this algorithm. The LinkRuleMiner algorithm modifies link structure and processing order of HMine algorithm. It has successfully removed link adjustment from H-Mine without any loss in performance and thus makes it possible to do parallelization on the algorithm efficiently. Therefore, the LinkRuleMiner algorithm that has no link adjustment made it possible to build parallel algorithm that requires no data exchange or any communications between each node in the middle of mining process. This allows us to build ideal parallel algorithm in shared disk environment and further to design parallel algorithm that exchanges data and communicates between each node in an efficient way in shared nothing environment. The figure 2 has 10 different association rules, which has different confidence values, from these rules, the high confidence rule has major association between activities and the minimum confidence rule has the minor association between activities. Also, these rules identify the relationship between the processes of dyeing. The one or more activities are combined in some rules, because more than one rule can participate in the same treatments. Hence, the dependency is identified very easily even for high number of event logs. But in the case of process mining algorithms HM and DWS it is not possible to identify the association between activities, but the DWS algorithm produce the discriminant rule, which has the relationship between activities, but this does not give the confidence measures. Therefore, from this we conclude that the association rules were very easy to understand and very helpful to identify the importance of activities and also the sequence of operations with the help of support and confidence features available in this algorithm. Hence, the dyers can easily identify the interrelationship between treatments, dependant, independent treatments and worker workload. Before concluding the comparative study the following experiment also conducted for Jayabala dyeing unit. This event has hundred shades. The hundred shades dyeing process of Jayabala dyeing unit computes the association rules in 0.124 seconds. This has the 10 different rules and each represents the different confidence, lift values. It is shown in the figure 3 and 4.
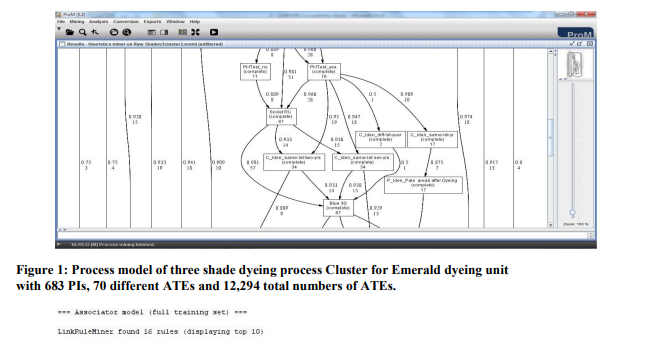
 Figure 4. Association rule mining Process model using LRM algorithm of hundred shades dyeing process for Jayabala dyeing unit of Whole log with 600 PIs, 262 different ATEs and total number of ATEs of 10,200 with execution time
Figure 4. Association rule mining Process model using LRM algorithm of hundred shades dyeing process for Jayabala dyeing unit of Whole log with 600 PIs, 262 different ATEs and total number of ATEs of 10,200 with execution time
LIMITATIONS OF THE LINKRULEMINER ALGORITHM
The association rule mining algorithm LRM has limitations with respect to frequent pattern by comparing with other algorithms available in traditional data mining. These limitations are stated below.
- Every association rule algorithm first generates frequent itemsets and then derives association rules from these frequent itemsets. Computational requirements for frequent itemset generation are generally more expensive than those of rule generation. When the value of the support thresholds is lowered it results in more itemsets declared as frequent. This increases the computational complexity of the algorithm because candidate itemsets must be generated and counted. The maximum size of frequent itemsets also increases with lowering the support threshold values. With this increase, the algorithm has to make more passes over the dataset. The total number of iterations required by the algorithm is kmax +1, where kmax is the maximum size of the frequent itemsets. Therefore, when lower support values are given to the algorithm to generate rules involving low frequent activities, the computational complexity also increases, thereby degrading the performance of the LRM in terms of computation time.
- When more itemsets (activities or group of activities) are declared as frequent itemsets more space is needed to store the support count of these items. This increase in the number of events increases the computation and I/O costs as larger number of candidate itemsets will be generated by the algorithm.
- The Apriori algorithm makes repeated passes over the data set therefore its run time increases with the size of the dataset. If the number of PIs in the event log is large the runtime for the algorithm also increases. For the LRM algorithm also the computation time increases linearly with an increase in the number of PIs.
- Also if the width of PIs is large i.e. the number of ATEs contained in a PI is large then the number of hash tree traversals performed during the support counting is also increased. This also consumes a lot to time.
- The association rule algorithms do not deal with length-one-loops. For example, if an event log contains traces of the type ?…aa…? it does not generate a rule showing that the task 'a' is in loop with itself. So, this information is missing in the LRM. But it is capable of dealing with loops involving more than 1 task i.e. length two or three loops.
- The confidence measure ignores the support of the itemset in the rule consequent. Due to this some high confidence rules can sometimes be misleading [9]. A better metric like the lift can be used to indicate interesting rules. Lift is a metric that also considers the support count of an association rule.
- Practically, by varying the values of the confidence and support parameters in the Apriori algorithm hundreds of association rules can be generated. But many of these rules are redundant and do not provide any new information. So, the search of interesting and non-redundant association rules is a very popular research topic.
- In the LRM, it is identified that the user can use the original Apriori algorithm but it is also identified that the user can apply the concept of interesting rules to retain only the non redundant rules. That means that the user can still take the output of the Apriori and then apply our filters. This consumes extra memory and time as many frequent itemsets are computed without any use as the rules that may be generated from them are eventually discarded because they may be redundant rules. It means a new concept for the association rule algorithm should be proposed that generates only the nonredundant rules and the frequent itemsets are generated accordingly.
- The frequent itemset generation in the FPGrowth algorithm is also computationally expensive. The latter minimizes the number of database passes by representing the transactional dataset in vertical layout (storing the list of transaction identifiers) rather than the horizontal layout storing the transactions themselves.
References:
REFERENCES
1. A.J.M.M. Weijters, W.M.P. van der Aalst, and A. K. Alves de Medeiros. Process Mining with the HeuristicsMiner Algorithm. BETA Working Paper Series, WP166, Eindhoven University of Technology, Eindhoven, 2006.
2. A.J.M.M. Weijters and W.M.P. van der Aalst. Workflow Mining: Discovering Workflow Models from Event-Based Data. In C. Dousson, F. H¨oppner, and R. Quiniou, editors, Proceedings of the ECAI Workshop on Knowledge Discovery and Spatial Data, pages 78–84, 2002.
3. R. Agrawal, D. Gunopulos, and F. Leymann. Mining Process Models from Workflow Logs. In Sixth International Conference on Extending Database Technology, pp. 469– 483, 1998.
4. J. Herbst and D. Karagiannis. An Inductive Approach to the Acquisition and Adaptation of Workflow Models. In M. Ibrahim and B. Drabble, editors, Proceedings of the IJCAI‘99 Workshop on Intelligent Workflow and Process Management: The New Frontier for AI in Business, pages 52– 57, Stockholm, Sweden, August 1999.
5. Prom Framework: www.processmining.org
6. Van der Aalst, W.M.P., Weijters, A.J.M.M., Maruster, L. Workflow Mining: Discovering Process Models from Event Logs, IEEE Transactions on Knowledge and Data Engineering, 16, pp: 1128-1142, 2004.
7. J. Herbst. A Machine Learning Approach to Workflow Management. In Proceedings 11th European Conference on Machine Learning, volume 1810 of Lecture Notes in Computer Science, Springer-Verlag, Berlin, pp. 183–194, 2000.
8. Dumas. M, van der Aalst. W.M.P. Process Aware Information Systems: Bridging People and Software through Process Technology, John Wiley & Sonc: Hoboken, New Jersey, 2005.
9. P. Tan, M. Steinbach and V. Kumar. Introduction to Data Mining. Addison Wesley, 2006.
|
 IJCRR
IJCRR 





 This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License





